Football Simulation Agent Framework
Overview
Kaggle Simulation Competition — Google Research Football with Manchester City F.C.
This competition challenged participants to build AI agents that play football in Google Research’s Football Environment, a physics-based 3D simulation. Teams competed by submitting agents that were matched against each other on Kaggle’s servers, with final rankings determined by Elo-style ratings from thousands of matches.
What I Built
Docker Environment
Created a containerized setup for the Google Football simulation environment with integrated Jupyter notebooks, enabling rapid prototyping and consistent reproducibility across machines. The Docker setup packages all dependencies (OpenAI Gym, Google Football env, TensorFlow) into a single portable image.
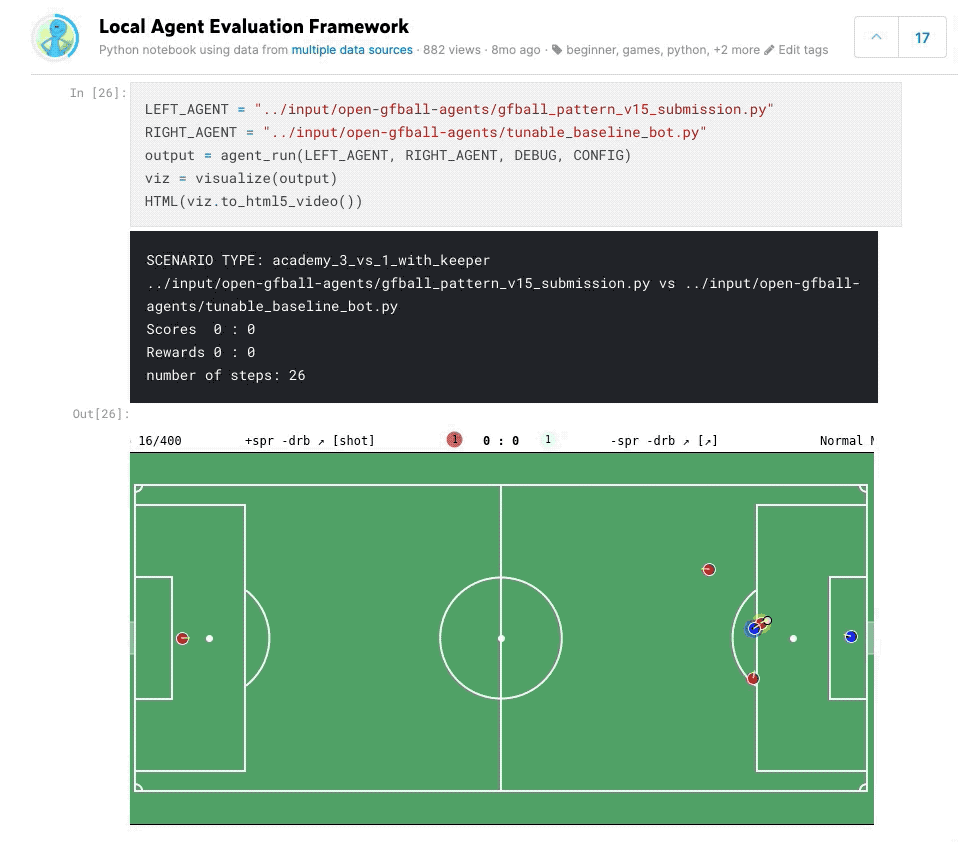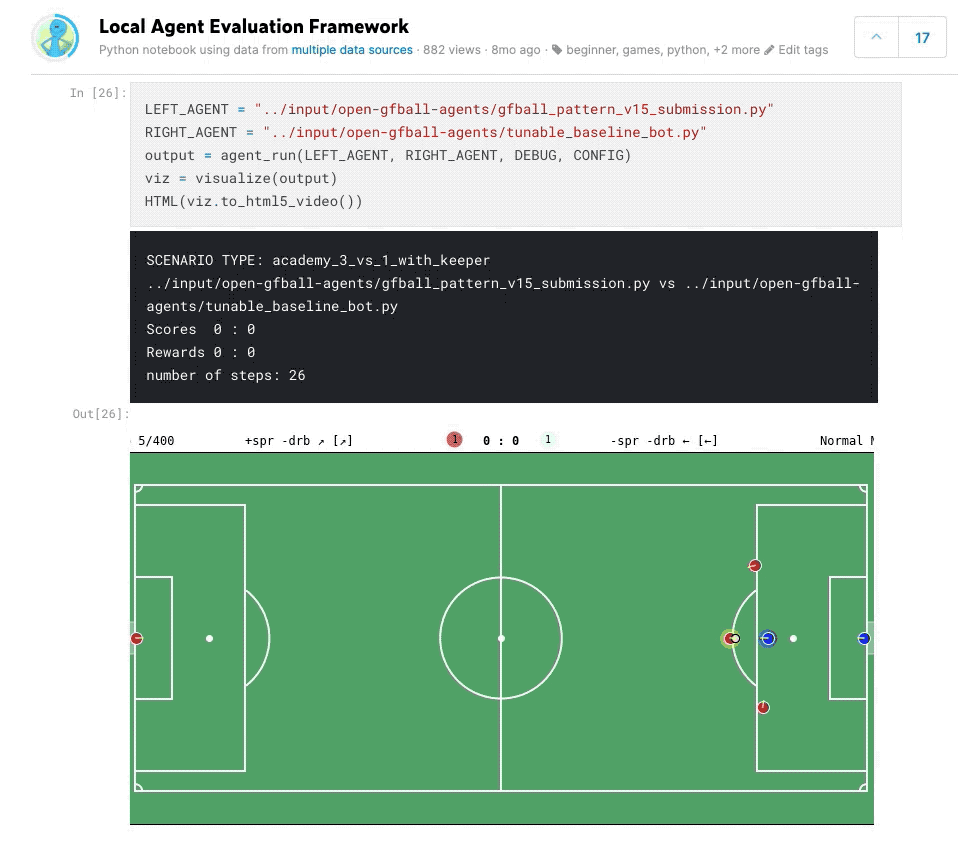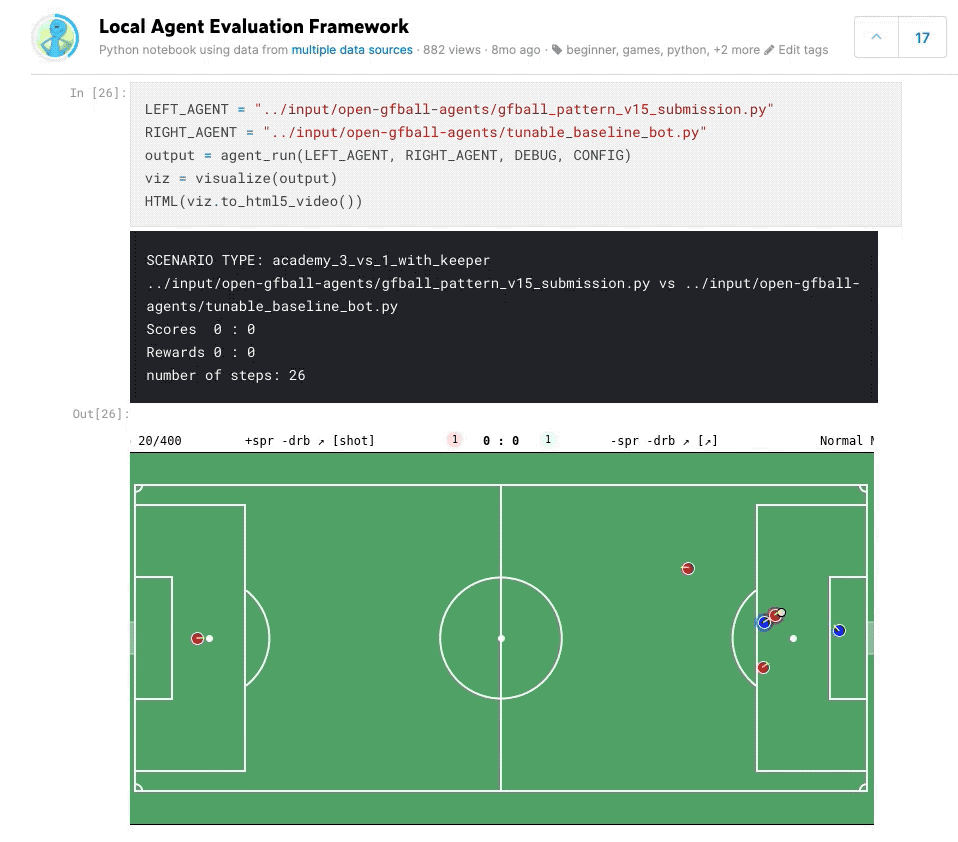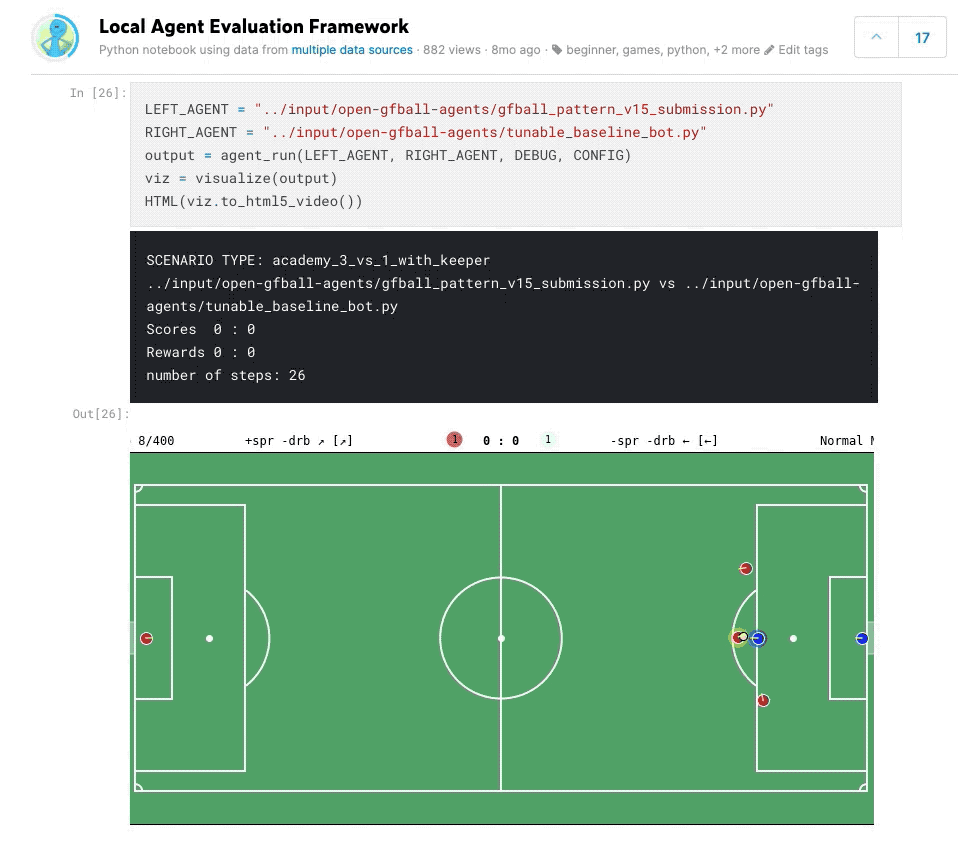
Agent Pool Play Framework
Built a local tournament framework to evaluate agents against each other before submitting to Kaggle. This allowed running round-robin matches between different agent versions, tracking win rates, goal differentials, and behavioral patterns — much faster iteration than waiting for Kaggle’s evaluation queue.
ML Agent Exploration
Experimented with multiple approaches to agent design:
- Rule-based agents with handcrafted game state heuristics (positioning, ball possession, pass selection)
- Reinforcement learning approaches using the environment’s reward signal
- Imitation learning from high-performing rule-based agents as training signal
- Analysis of game state representations and action space design choices
Technical Details
Environment: Google Research Football Environment (OpenAI Gym compatible)
Stack: Python, Docker, Jupyter, TensorFlow, OpenAI Gym
Key challenges:
- Game state representation: 115-dimensional vector encoding player positions, ball state, and game context
- Action space: 19 discrete actions (movement, passing, shooting) requiring strategic sequencing
- Reward shaping: Sparse rewards (goals) made RL training difficult; experimented with dense reward functions based on ball progression and positioning